More Human Than Human: Building Voice AI That Actually Listens


TL;DR: Voice AI feels robotic because it ignores how humans actually converse. When you talk to someone, they don’t just wait silently—they constantly signal engagement with small sounds (“mm-hm,” “yeah,” “right”) that happen during your speech, not after. These “backchannels” fire 200-700ms after specific cues like micro-pauses and volume drops. I’m building Voxio-bot to do exactly this: real-time prosodic analysis, overlapping acknowledgments at reduced volume, and context-aware responses. After 15 years building voice platforms (Voxeo, VoiceXML standards, billions of calls), I’m finally building voice AI that listens the way humans listen.
I spent 15 years making machines talk more like humans. That works great now. Next we need to make them "listen" like humans.
In 1999 I started Voxeo with some great co-founders. We had a simple premise—web developers should be able to build voice applications as easily as web applications. We were Twilio ~10 years before Twilio, but with waaay better customer service. We sold it in 2013.
Not bitter but we shouldn't have sold Voxeo. It was a magical place.
Voxeo created the (then) largest voice hosting platform in the world. It powered billions of phone calls. We helped write the standards (VoiceXML, CCXML, WebRTC) that defined how internet-based voice applications work. We grew to 220,000 developers, got acquired, and we also spun off a version of the tech as Tropo right before we sold Voxeo. Tropo was quickly acquired by Cisco in 2015.
The voice interfaces we built were functional. Efficient. Useful. And yet still very inhuman.
Initially (~200o) it was “Say Sales or press 1 for sales. Say Support or press 2 for support.” That’s not conversation. That’s a menu with a microphone.
By 2013 things became more natural; but it was still... un-natural. We constantly worked on making it all work better; we even built our own speech recognition engine–which was a big deal back then.
Now, working on Clawdbot/OpenClaw, I’m (amongst a dozen other things) finally building what I always wanted to build: voice AI (and video, more on that later) that doesn’t just understand words—it understands the rhythms of human conversation.
What No (AI) is Saying
Modern voice AI has solved the hard technical problems. Speech recognition is remarkably accurate. Language models can generate coherent, contextual responses. Text-to-speech sounds increasingly natural.
So why does talking to voice AI still feel… off?
Because conversation isn’t just words. It’s two-way timing. It’s the “mm-hm” someone murmurs while you’re mid-sentence. It’s the “I see” they say the moment you finish a thought. It’s the subtle sounds of presence that tell you someone is actually there, actually listening.
Remove these signals and you get what we have today: voice assistants that feel like talking into a uncaring void and waiting for a response to materialize.
What Humans Actually Do
I’ve been studying conversation analysis research—decades of linguistics work that maps exactly how humans communicate.
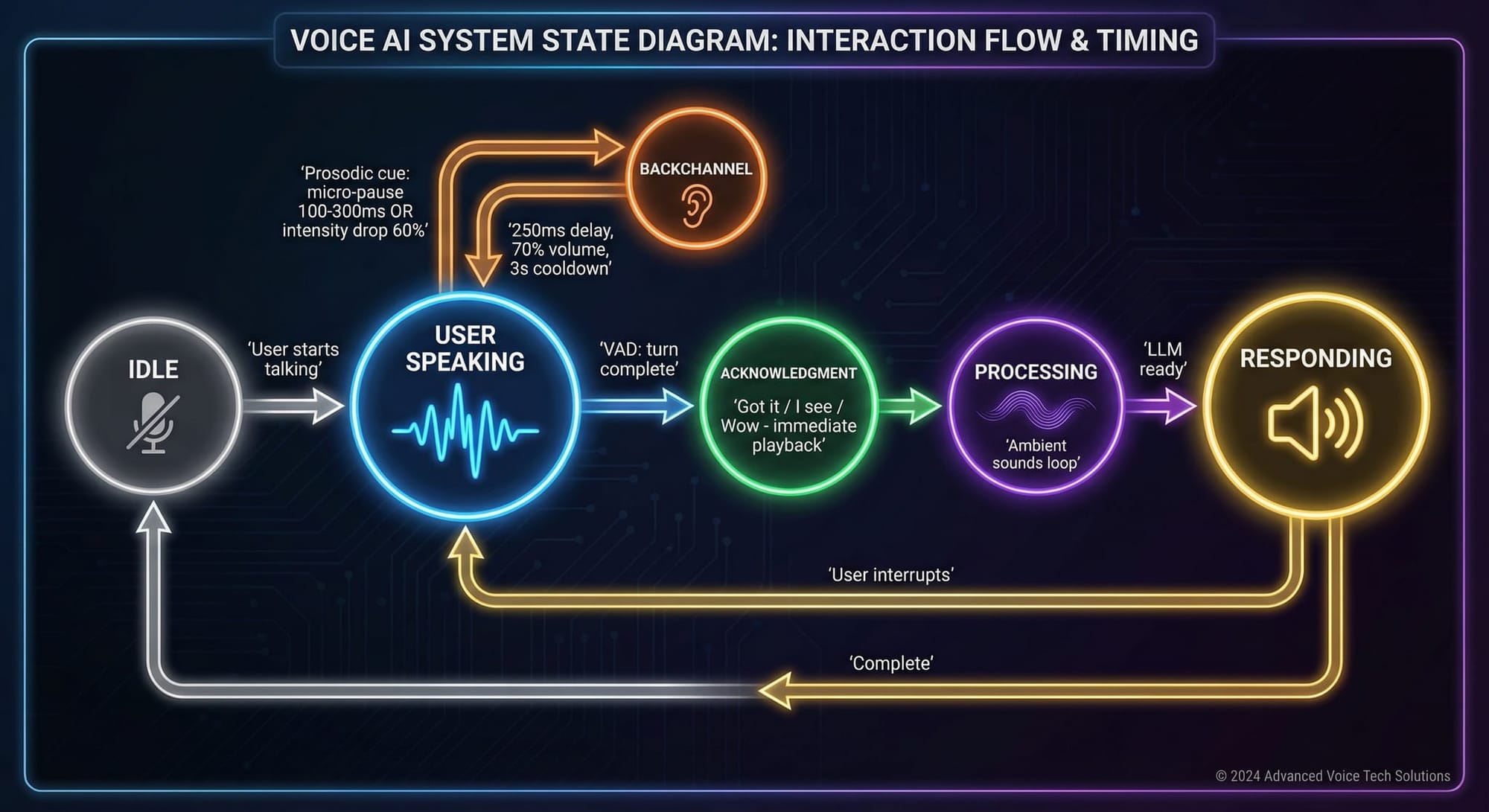
When you talk to another person, they’re not just waiting for you to finish so they can respond. They’re constantly signaling engagement through what linguists call “backchannels”—quick vocalizations like “yeah,” “mm-hm,” and “uh-huh” that happen during your speech, not after it.
These aren’t interruptions. They don’t claim the conversational floor. They explicitly say: “I’m with you. Keep going.”
These "backchannel cues" are not random. Research by Ward and Tsukahara mapped the precise moments when listeners naturally produce these signals. They occur 200 to 700 milliseconds after specific prosodic cues: micro-pauses in speech (100-300ms), drops in volume, falling pitch patterns. Your brain recognizes these cues and responds automatically. It’s so natural you don’t even notice you’re doing it.
Until a machine fails to do it. Then you notice immediately.
Building Something Different
Voxio-bot is a realtime, conversational, voice and video interface that runs on any modern web-browser (desktop, iPhone, Android, etc). Technically it can work with any Agent, but I’m focused on bringing it to OpenClaw.
The system monitors speech in real-time, analyzing audio for those same prosodic cues that humans respond to;
- When you pause briefly mid-sentence, it produces a variety of soft “mm-hm"s
- When your volume drops at the end of a phrase, it might say “right” or “sure.”
- These responses fire within 250 milliseconds of the cue—in the natural human timing range.
Volume matters too. Backchannels in human conversation are softer than primary speech. They’re background acknowledgment, not competition for attention. So I reduce their volume below normal output.
And crucially, they overlap. In natural conversation, a listener’s “yeah” often occurs while the speaker is still talking. It doesn’t wait for silence. Neither do we.
The Same Word, Different Meanings
One of the most fascinating discoveries in this work is how much intonation matters.
The word “yeah” can mean completely different things depending on how you say it. With falling pitch, it signals closure—acknowledgment that could end the exchange. With rising pitch, it’s an invitation to continue. With high pitch and volume, it expresses surprise or strong agreement.
The same pattern applies to most conversational tokens. “Right” with falling intonation means “I understand.” “Right?” with rising intonation is checking for confirmation. Context and prosody transform the same syllables into entirely different conversational moves.
Currently, I control this through punctuation cues to the speech generation engine—periods tend toward falling intonation, question marks toward rising. It’s imperfect. Future versions will cache multiple prosodic variants of each token and select them based on conversational context. The goal is a system that can respond “Really?” with genuine surprise or “Really.” with simple acknowledgment, depending on what the moment calls for.
Beyond Backchannels
When you finish speaking, something else happens. The listener produces an acknowledgment—”Got it,” “I see,” “Interesting”—that does something backchannels don’t: it claims the floor. It signals that they’ve received your message and are now preparing to respond.
This serves a critical practical function. I pre-create (generate synthesized speech) and cache everything I described above so they can be played immediately without delay. In contrast, language models need time to process and generate responses. Without acknowledgment, that processing time is silence. And silence in conversation creates anxiety. Did they hear me? Is the connection broken? Are they ignoring me?
An immediate “Hmm” or “Got it” transforms the experience. The system heard you. It’s thinking. A real response is coming.
Not all acknowledgments are equal, either. Linguists distinguish between receipt tokens (“Got it”), change-of-state markers (“Oh!” when learning something new), and assessments (“Wow,” “Nice,” “Interesting”) that evaluate what was said.
Assessments matter for warmth. If you tell someone you got promoted and they respond with “Got it,” that feels cold. “Wow!” or “Nice!” acknowledges the same information while displaying appropriate enthusiasm. It’s the difference between functional exchange and human connection.
Why This Matters
I believe everything we build for Clawdbot/OpenClaw has to be the best in the world. Not competitive. Not good enough. The best.
For voice and video AI, “best” means something specific: it has to feel like talking to someone who’s actually present, actually engaged, actually listening. So I've implemented everything discussed above in Voxio-bot.
The irony is that achieving this requires implementing things most people never consciously notice. No one thinks about backchannels in their daily conversations. No one analyzes the prosodic cues they respond to. These patterns are so deeply automatic that they’re invisible.
But their absence is immediately felt. That’s why every voice assistant—from Siri to Alexa to the fanciest demo from the latest AI lab—still feels subtly wrong. They’ve focused on understanding words and generating responses. They’ve ignored the conversational fabric those words are woven into.
I'm not even sure anyone else is implementing these things today. I mean they must be, but I don't know where.
More Human Than Human
I spent fifteen years building voice platforms that processed billions of calls. We helped write standards that defined an industry. And the honest truth is that we were building better phone trees.
Now I’m building something different. Voice AI that doesn’t just respond—it participates. That doesn’t just understand words—it understands conversation. That sounds natural not because of better synthesis, but because it behaves the way humans actually behave.
The technology finally exists to do this right. Real-time audio analysis. Lightning-fast synthesis. Models sophisticated enough to understand context. What’s been missing is the will to sweat the details that don’t show up in demos—the details that make the difference between impressive and genuinely human.
More human than human. That’s the standard. Anything less is just a talking computer.
I've spent ~3 AI-weeks (one AI-week = ~90 normal weeks) building this, and about 80 hours using it while I drive in the car. Not out of boastfulness, but out of pride: it's outstanding. It feels more human than any voice UI I've ever interact with.
In fact, I've written almost all of my recent blog posts by talking with it. Including this one.
As I said there must be other people out there doing these things, I just haven't seen (or heard) them. I could maybe patent this, or lock it all up in a NewCo, but this (and my work on OpenClaw overall) are my gift to my friends and the world.
As my good friend Jason Eichenholz says, "Why not change the world?". I couldn't agree more. Just like. he does with Jonathans Landing, I'm doing it openly and for free–but via OpenClaw, Voxio-bot, Deft Directive ... and more to follow.


